


En el mundo de la gestión de los datos se está produciendo una oleada de tecnologías y metodologías, cada una representada por sus propias palabras de moda y términos. Uno de los debates en cuanto a datos más candentes es la cuestión que me contaba el otro día un científico de datos de Google: ¿qué es mejor ETL o ELT? y cómo se relacionan con los datawarehouses y Data Lakes.
Para intentar clarificar el caos terminológico vamos a repasar cuáles son las diferencias y similitudes entre ETL y ELT, cuál es mejor, y ayudar a descifrar las palabras de moda: data lakes (lagos de datos) y datawarehouses.
Para hacer que los datawarehouses sean más accesibles a las herramientas analíticas tradicionales, los datos pueden organizarse ejecutándolos a través de un proceso de extracción, transformación, carga (ETL).
ETL
ETL es normalmente un proceso continuo y con un flujo de trabajo bien definido. Con una metodología ETL primero extraemos los datos de fuentes de datos homogéneas (bases de datos relacionales o RDBMS) o heterogéneas (los datos se almacenan como ficheros). Luego, los datos se limpian, se enriquecen, se transforman. Las transformaciones pueden incluir la aplicación de cálculos, concatenaciones, anonimizaciones, agregaciones, etc., es entonces cuando finalmente se almacenan en el almacén de datos. En ETL los datos fluyen desde el origen al destino, el motor de transformación de procesos se encarga de cualquier cambio en los datos.

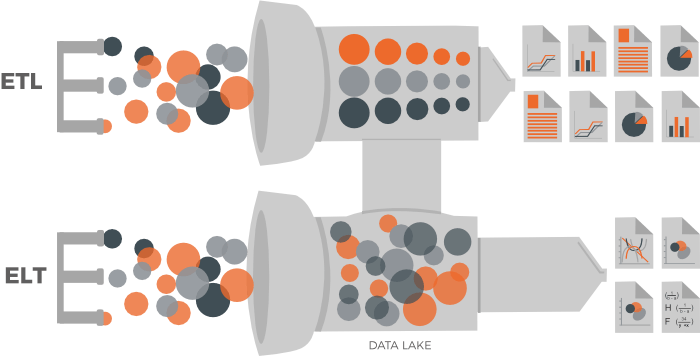
ELT
ELT (Extraer, cargar, transformar) es un método diferente de acercarse al flujo de datos, en el que los datos extraídos se cargan primero en el sistema de destino. Las transformaciones se realizan después de que carguemos los datos en el almacén de datos. En lugar de transformar los datos antes de que se escriban, ELT permite que el sistema de destino realice la transformación. Los datos primero se copian en el data lake y luego se transforman in situ. El ELT generalmente funciona bien cuando el sistema objetivo es lo suficientemente potente como para manejar transformaciones a gran escala. ELT generalmente se usa con bases de datos NOSQL como el clúster de Hadoop, un dispositivo de datos o una instalación en la nube. Las bases de datos analíticas como Amazon Redshift o Google BigQuery se usan a menudo en pipelines ELT porque son altamente eficientes para realizar transformaciones.
Dudas
Hay una serie de otras preguntas clave que deben plantearse al considerar los datawarehouses frente a los data lakes. Preguntas como:
¿Debo primero enmascarar los datos de PII (correo electrónico y direcciones IP) para estándares de privacidad como GDPR, CCPA y HiPPA antes de cargar en un lago o almacén?
¿Cuál es la naturaleza de mis datos? ¿Necesito Real Time o en batch me sirve? ¿Estructurado o no estructurado?
¿Qué pasa con la volatilidad de los datos?
¿Quiénes son las personas que necesitan consultar mi almacén de datos, cuáles son sus habilidades? ¿Cuáles son los tipos de consultas que necesitarán realizar?
Diferencias ETL y ELT
| Parámetros | ETL | ELT |
| Procesamiento | Los datos se transforman en el servidor de almacenamiento intermedio y luego se transfieren al Datawarehouse. | Los datos permanecen en el data lake. |
| Código de uso | Usado para: – Transformaciones de computación intensiva – Pequeña cantidad de datos | Cantidades grandes de datos |
| Transformación | Las transformaciones se realizan en el servidor ETL / área de ensayo. | Las transformaciones se realizan en el sistema de destino. |
| Tiempos de carga | Los datos se cargan primero en el almacenamiento intermedio y luego se mueven al sistema objetivo. Tiempo intensivo. | Los datos cargados en el sistema de destino solo una vez. Más rápido. |
| Tiempos de Transformación | El proceso ETL necesita esperar a que se complete la transformación. A medida que crece el tamaño de los datos, aumenta el tiempo de transformación. | En el proceso ELT, la velocidad nunca depende del tamaño de los datos. |
| Tiempos de mantenimineto | Necesita altos niveles de mantenimiento ya que necesita seleccionar datos para cargar y transformar. | Bajo mantenimiento ya que los datos están siempre disponibles. |
| Complejidad de implementación | En una etapa temprana, es más fácil de implementar. | Para implementar el proceso de ELT, la organización debe tener un conocimiento profundo de las herramientas y los skills necesarios. |
| Soporte para Data warehouse | Modelo de ETL utilizado para datos locales, relacionales y estructurados. | Se utiliza en una infraestructura de cloud escalable que admite orígenes de datos estructurados y no estructurados. |
| Soporte Data lake | No soportado. | Permite usar un Data lake con datos no estructurados. |
| Complejidad | El proceso ETL carga solo los datos importantes, como se identificaron en el momento del diseño. | Este proceso implica el desarrollo desde la salida hacia atrás y la carga de solo datos relevantes. |
| Costes | Costes elevados para pequeñas y medianas empresas. | Bajos costes de entrada utilizando plataformas de Software as a Service. |
| Búsquedas | En el proceso de ETL, tanto los hechos como las dimensiones deben estar disponibles en el área de preparación. | Todos los datos estarán disponibles porque la extracción y la carga se producen en una sola acción. |
| Agregaciones | Aumento de la complejidad con la cantidad adicional de datos en el conjunto de datos. | El poder de la plataforma de destino puede procesar una cantidad significativa de datos rápidamente. |
| Cálculos | Sobrescribe la columna existente o necesidad de adjuntar el conjunto de datos y empujar a la plataforma de destino. | Permite agregar fácilmente la columna calculada a la tabla existente. |
| Madurez | El proceso se utiliza desde hace más de dos décadas. Está bien documentado y las mejores prácticas fácilmente disponibles. | Concepto relativamente nuevo y complejo de implementar. |
| Hardware | La mayoría de las herramientas tienen requisitos de hardware únicos que son caros. | En formato SaaS el coste de hardware no es un factor crucial. |
| Soporte para datos no estructurados | En su mayoría soporta datos relacionales | Soporte para datos no estructurados fácilmente disponibles. |
Resumen
La conclusión es que el lago de datos tiene un potencial casi ilimitado, pero requiere unos conocimientos elevados para llevar a cabo la serie de transformaciones antes de lograr tener la suficiente calidad como para sacar provecho a los datos almacenados. Un datawarehouse, por el contrario, requiere una inversión significativa por adelantado, pero a cambio ofrece la capacidad de analizar todo fácilmente, y las habilidades que se requieren para consultarlo (generalmente SQL) suelen ser más fáciles de encontrar entre el equipo de analistas.