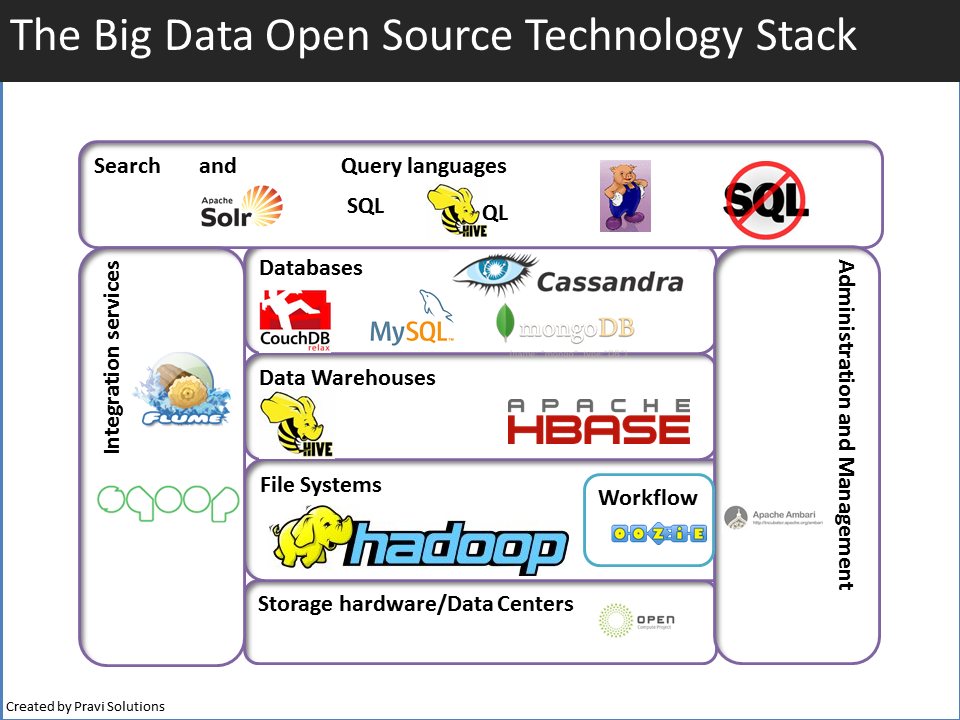
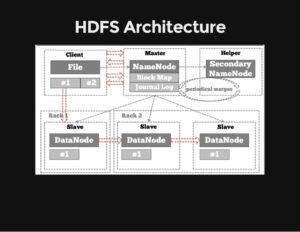
Si hay un área de tecnología de información que está teniendo un crecimiento vertiginoso es el del BigData. Gracias al trabajo de multitud de compañías y desarrolladores aportando en modo open source el stack de software relacionado con Big Data también va quedando obsoleto fruto de la continua evolución de las herramientas y necesidades del mercado.
Big Data Stack 1.0
El primer stack o set de componentes de software necesarios para crear o completar una plataforma sin necesidad de añadidos para soportar aplicaciones, denominado Hadoop, se basaba en el software de los gigantes de Internet (Google, Yahoo, Facebook) parte del cual se hicieron públicos hace una década. El núcleo del primer stack Hadoop se componía de GFS / HDFS + MapReduce + Bigtable / HBase + MapReduce. Estas tecnologías permitieron a las startups de Internet escalar su infraestructura con hardware no especializado pero con el tiempo los problemas y necesidades comenzaron a acumularse a pesar de las continuas actualizaciones y versiones adaptadas.

Big Data Stack 2.0
El Google File System (GFS) es un gran sistema distribuido de almacenamiento pero en cuanto se empieza a hacer uso intendivo de metadatos llegamos a un problema SPF (Single Point of Failure). MapReduce es muy resistente pero lleva mucho tiempo reiniciar las caídas. Debido a esto en Google empezaron a diseñar una versión 2.0 de su stack Big data. Veamos las principales características de estas herramientas:
Colossus (GFS II) será la evolución del Google File System. Cada data center tienen su propio cluster Colossus con suficientes discos para dar soporte a miles de usuarios concurrentes de BigQuery. Colossus también gestiona la replicación, recuperación de discos y gestión distribuida (solucionando el problema de SPF). Y es lo suficientemente rápido como para permitir a BigQuery un rendimiento similar a muchas bases de datos en memoria, siendo mucho más económico, aun siendo una infraestructura altamente paralelizada, escalable, duradera y eficiente. BigQuery aprovecha el formato de almacenamiento columnar ColumnIO y el algoritmo de compresión para almacenar datos en Colossus de la manera más óptima para leer grandes cantidades de datos estructurados. Colossus permite a los usuarios de BigQuery escalar a decenas de petabytes en almacenamiento sin problemas, y sin necesidad de añadir recursos de hardware mucho más caros, típico con la mayoría de las bases de datos tradicionales.
Megastore es un nuevo sistema de almacenamiento desarrollado para satisfacer los requisitos de los servicios interactivos online. Megastore combina la escalabilidad de un almacén de datos NoSQL con la conveniencia de un RDBMS tradicional de una manera novedosa, proporcionando garantías de consistencia sólida y alta disponibilidad. Proporciona semántica ACID (Atomicidad, Consistencia, Aislamiento y Durabilidad) completamente serializable dentro de particiones granulares de datos. Este particionamiento nos permite replicar de forma síncrona cada escritura a través de una red con latencia razonable y soportar una conmutación continua entre datacenters. El Megastore aprovecha el algoritmo de replicación Paxos.
Cloud Spanner es el primer y único servicio de base de datos relacional que es fuertemente consistente y escalable horizontalmente. Con Cloud Spanner podemos disfrutar de todos los beneficios tradicionales de una base de datos relacional: transacciones ACID, esquemas relacionales (y cambios de esquema sin tiempo de inactividad), consultas SQL, alto rendimiento y alta disponibilidad. Sin embargo, a diferencia de cualquier otro servicio de base de datos relacional, Cloud Spanner se escala horizontalmente, hasta cientos o miles de servidores, por lo que puede manejar una mayor cantidad de cargas de trabajo transaccionales. Con la escalabilidad automática, la replicación de datos síncrona y la redundancia de nodos, Cloud Spanner ofrece hasta un 99.999% de disponibilidad para sus aplicaciones de misión crítica. De hecho, el servicio Spanner interno de Google ha estado manejando millones de consultas por segundo de muchos servicios de Google durante años.
Cloud Dataflow es un servicio de gestión completo para ejecutar pipelines de procesamiento de datos en paralelo. Se componen de una serie de SDKs para construir pipelines para procesamiento de datos en batch o streaming.
FlumeJava. MapReduce y sistemas similares facilitan significativamente la tarea de escribir código paralelo de datos. Sin embargo, muchos cálculos del mundo real requieren un canal de MapReduces, y la programación y la gestión de estos pipelines puede ser difícil. De ahí FlumeJava, una biblioteca de Java que facilita el desarrollo, la prueba y la ejecución eficiente de pipelines de datos en paralelo. En el núcleo de la librería FlumeJava hay un par de clases que representan colecciones paralelas inmutables, cada una de las cuales soporta un número de operaciones para procesarlas en paralelo. Las colecciones paralelas y sus operaciones presentan una abstracción simple, de alto nivel y uniforme sobre diferentes representaciones de datos y estrategias de ejecución. Para permitir que las operaciones paralelas se ejecuten de manera eficiente, FlumeJava retrasa su evaluación, en lugar de construir internamente un gráfico de flujo de datos del plan de ejecución. Cuando finalmente se necesitan los resultados finales de las operaciones paralelas, FlumeJava optimiza primero el plan de ejecución y, a continuación, ejecuta las operaciones optimizadas en primitivas subyacentes apropiadas (por ejemplo, MapReduces). La combinación de abstracciones de alto nivel para datos en paralelo y el nivel de procesamiento, evaluación y optimización diferida y primitivas paralelas eficientes proporciona un sistema fácil de usar que se aproxima a la eficiencia de los pipelines optimizados a mano. FlumeJava está en uso activo por cientos de desarrolladores de pipelines dentro de Google.
Dremel es un sistema de consulta ad-hoc escalable e interactivo para el análisis de datos anidados de sólo lectura. Combinando árboles de ejecución multinivel y un diseño de datos columnar, es capaz de ejecutar consultas de agregación sobre tablas de billones de filas en cuestión de segundos. El sistema se escala a miles de CPUs y petabytes de datos, y tiene miles de usuarios en Google.
Y sí, no sólo de Google, también vemos propuestas para resolver el gran problema de big data con grandes productos de otros innovadores como Cloudera Impala, Redshift de Amazon, Apache Drill, Presto de Facebook, y más.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave A Comment