Events in DDD platforms use to be raised by interaction with external sources, and those events use to be generated from commands (updates, creations, deletions, or pure business actions). Distributed computing platforms receive messages from other systems and there is usually a gateway where those messages become events with a generic and standard format.
Users can also interact with APIs and raise other events that must be propagated over the platform in order to save the information or notify other services to affect other domain entities.
Events life-cycle is not a long term process, basically, we could summarize it like: “something has changed, and maybe someone is interested in this change” maybe our event can notify a service, and this service is forced to raise another event, but the life of this “consequence” should be similar than the one that triggered it. On the other hand, it’s easy to find business information related to dates, or temporal information, that should perform the transformation in our data. In this situation, we can face the problem that motivates this post. Events cannot wake themselves up.
A typical problem, expiration date
Let’s imagine we are working on an e-commerce platform, and maybe we have thought about creating object models called… I don’t know… price? (Maybe you could think this section is a plagiarism of Walmart labs post (1), but I swear I had to deal with exactly the same problem before reading its solution)
The prices can work like promotions in a certain way, but if the prices want to be dynamic, they need to work (activate, deactivate) in a temporal window. We can think in large promotion days like Black Friday, as window times for promotions, or even as activation periods for different prices.
Let’s suppose a typical situation related to event-streaming systems:
- Price is a model entity, and it has an attribute called “expiration_date” with a date value, and another called “status” with active/inactive value.
- An external system begins to load a bunch of active prices through a similar bunch of price-domain-events.
- Our asynchronous CQRS-based persist system is listening to our message’s middleware and quickly saves all prices in the persistence engine.
- Another service is also listening and refresh all prices in our cache system.
Users can see new prices, data is consistent and everything is running like it’s supposed to. Let’s have a beer, this streaming platform has been successfully designed.
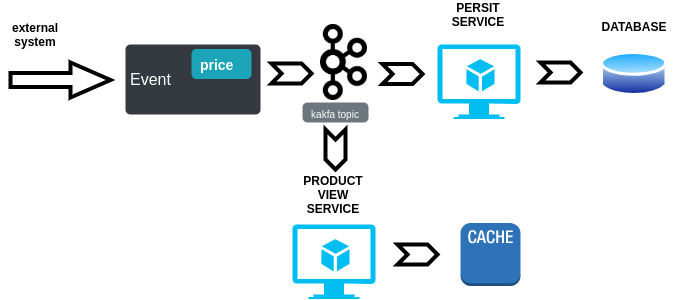
When space-time in our dimension reaches the date marked as the expiration date for one of our little prices, what should happen? This price should change its status and users should notice the change… but what really happens?
Absolutely nothing.
Our events cannot work with time attributes unless these attributes have only informative purposes. We can’t change entities and make notifications to other services. Our entire system depends on external systems to send every time information and that kind of event if some information must be changed. This could be a problem, or at least a great limitation to design event-based platforms.
So, how can we know then, if some promotion or some price has expired?
Solutions based on a distributed scheduler
Basically, all solutions for this problem are based on schedulers or distributed schedulers, this means many jobs searching over trillions of elements. If we are lucky we can have our entities distributed and well balanced over persistence systems and some entity-based designs to look for changes in small triggers.
Couchbase has proposed recently an eventing framework working on one of its services which could be a great solution for this problem. (2) Document insertions in the database are linked to small functions, and these functions can be scheduled to run when our attribute “expiration_date” time comes. Through Kafka connectors, each document can be transformed into a domain event and be released in the middleware.
Wallmart also has released Big Ben. This is a system that can be used by a service to schedule a request that needs to be processed in the future. The service registers an event in the scheduler and suspends the processing of the current request.
When the stipulated time arrives, the requesting service is notified by the scheduler and the former can resume processing of the suspended request.
Those are both good solutions to solve this problem, but we had an idea that could be simple (and therefore smart) and help with all of our cases.
Kafka to the rescue
Stream processing its maybe the greatest strength of Kafka. New features related to Kstreams and KTables are showing a new world of possibilities for software engineers and architects.
KTable is an abstraction of a changelog stream from a primary-keyed table. Each record in this changelog stream is an update on the primary-keyed table with the record key as the primary key.
A KTable is either defined from a single Kafka topic that is consumed message by message or the result of a KTable transformation. An aggregation of a KStream also yields a KTable.
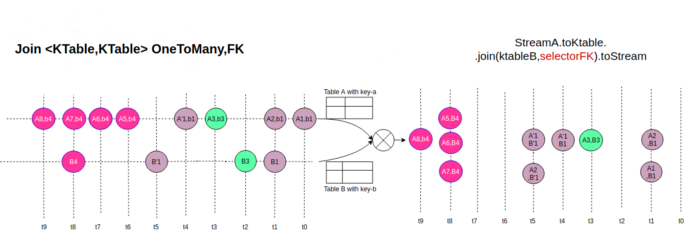
Since Kafka 2.4 KTable joins work as SQL joins, Foreign-key, many to one, joins were added to Kafka in KIP-213 (3).
This basically means that we can join events not only using its primary key, we can also join events in different topics by matching any of its attributes.
Our solution
What do foreign keys in KTables have to do with our static events?
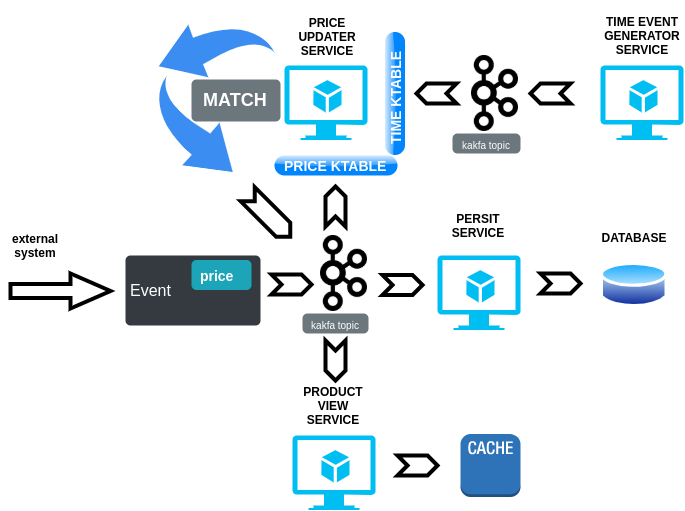
Let’s think about our original problem with expiration dates. In a pure event sourcing system, we would have a topic dedicated to price events.
Creation, update, and deletion events are allocated on the same price topic.
On one hand, we can develop a really easy service based on a simple scheduler. Its responsibility is sending time events each minute, or each second if we need more accuracy. On the other one, we have to deploy a joiner service, the “Updater”. This service is listening from time event topic and price (or any other domain) event topic. Its entry points are two KTables, and these KTables are allowed to store a very big set of data.
When the timed event arrives in time topic (and time KTable), our update service seeks over domain KTable if one specified field matches with this date. If there are one or many matches, we can send a new update event with our price, or even we can put some logic into the update-service in order to change the price entity status.
Show me the code!
Ok, this could be a good solution but, how many lines of code do you need for a joiner?
Less than ten lines:

Performance
We can think in many scenarios for event expiration or release. We have tested scenarios for 0.5–1%, 5–10%, and 50% of business events affected for time events.
Let’s imagine the worst situation, one in which time is over midnight, and it begins a very special date, where almost half of our entities have to change its status.
As you can see, we have filled our topics with 4 and 8 million messages in order to stress Ktable join processors.

Generalization
What do we need to use this solution across all our domains? Not much work, really.
We just need to configure our time scheduler service (It can be fault-tolerant through replication because we can filter replicated messages with the same temporal key in destination topic) and one “joiner” service for each entity topic.
In each domain, it can be found many domain entities “allocated” in a Kafka topic, each one of this topic receives events related to these entities, and those events can be resent or reloaded in our event pipeline when its temporal field matches with timed events.
Placing a few dedicated services, our platform can “reload” events itself leaving that responsibility in Kafka, and it also guarantees consistency and really good fault tolerance levels.
Acknowledgments
I would like to thank Rafael Serrano and Jose Luis Noheda the support received, Soufian Belahrache (Black belt on KTables), and Francisco Javier Salas for their work on this POC, and Juan López for the peer review.
References
2. https://dzone.com/articles/implementing-a-robust-portable-cron-like-scheduler
3. https://cwiki.apache.org/confluence/display/KAFKA/KIP-213+Support+non-key+joining+in+KTable


