
La computación sin servidor, o simplemente Serverless computing, es uno de los temas más de moda en el mundo de la arquitectura de software. Los «tres grandes» proveedores en la nube (Amazon, Google y Microsoft) invierten mucho en Serverless, y hemos visto muchos lanzamientos de libros, proyectos de código abierto, conferencias y proveedores de software dedicados al tema. Pero, ¿qué es Serverless y por qué (o no) vale la pena considerarlo? En este artículo espero poder ilustrarte un poco sobre estas preguntas.
Para empezar vamos a ver qué significa Serverless. Entraremos en los beneficios e inconvenientes del enfoque más adelante.
Las arquitecturas sin servidor (serverless computing) son diseños de aplicaciones que incorporan servicios de «Backend as a Service» (BaaS) de terceros, y / o que incluyen código personalizado ejecutado en contenedores efímeros administrados en una plataforma «Functions as a Service» (FaaS). Al utilizar este modelo, y otros conceptos relacionados como las aplicaciones de una sola página, tales arquitecturas eliminan gran parte de la necesidad de un componente de servidor siempre activo como se venía haciendo tradicionalmente. Las arquitecturas sin servidor pueden beneficiarse de una reducción significativa en el coste operacional, la complejidad y el tiempo de ingeniería de procesos, sacrificando según qué casos, una mayor dependencia de proveedores y servicios de soporte relativamente inmaduros.
¿Qué es serverless computing?
Al igual que muchas tendencias en software, no hay una visión clara de qué es Serverless. Para empezar, abarca dos áreas diferentes pero superpuestas:
Serverless se utilizó por primera vez para describir aplicaciones que incorporan de forma significativa o completa aplicaciones y servicios de terceros alojados en la nube, para administrar la lógica y el estado del servidor. Estas son típicamente aplicaciones de «rich client» (piense en aplicaciones web de una sola página o aplicaciones móviles) que utilizan el vasto ecosistema de bases de datos accesibles en la nube (por ejemplo, Parse, Firebase), servicios de autenticación (por ejemplo, Auth0, AWS Cognito), etc. Estos tipos de servicios se describieron anteriormente como «Backend como servicio», y usaremos «BaaS» como abreviatura en el resto de este artículo.
Serverless también puede significar aplicaciones donde la lógica del lado del servidor aún está escrita por el desarrollador de la aplicación, pero, a diferencia de las arquitecturas tradicionales, se ejecuta en contenedores de cómputo sin estado que son activados por eventos, efímeros (pueden durar solo una invocación) y administrados completamente por un tercero. Una forma de pensar en esto es «Funciones como servicio» o «FaaS«. AWS Lambda es una de las implementaciones más populares de una plataforma de Funciones como Servicio en la actualidad, pero hay muchas otras.
En este artículo, nos centraremos principalmente en la segunda, FaaS. No solo es el área de Serverless más novedosa, sino que tiene diferencias significativas en la forma en que generalmente pensamos acerca de la arquitectura técnica.
BaaS y FaaS están relacionados en sus atributos operacionales (por ejemplo, sin administración de recursos) y se usan con frecuencia juntos. Todos los grandes proveedores de la nube tienen «servicios sin servidor» que incluyen productos BaaS y FaaS, por ejemplo, aquí está la página de productos sin servidor de Amazon. La base de datos Firebase BaaS de Google tiene soporte explícito de FaaS a través de Google Cloud Functions para Firebase.
También existe una vinculación similar entre las dos áreas en las empresas más pequeñas. Auth0 comenzó con un producto BaaS que implementó muchas facetas de la administración de usuarios y, posteriormente, creó el servicio complementario de FaaS Webtask. La compañía ha llevado esta idea aún más lejos con Extend, que permite que otras compañías de SaaS y BaaS agreguen fácilmente una capacidad de FaaS a los productos existentes para que puedan crear un producto Serverless unificado.
Algunos ejemplos
Aplicaciones controladas por UI
Pensemos en un sistema tradicional de tres capas orientado al cliente con lógica del lado del servidor. Un buen ejemplo es una aplicación de comercio electrónico típica.
Tradicionalmente, la arquitectura tendrá un aspecto similar al siguiente diagrama. Digamos que está implementado en Java o Javascript en el lado del servidor, con un componente HTML + Javascript como cliente:
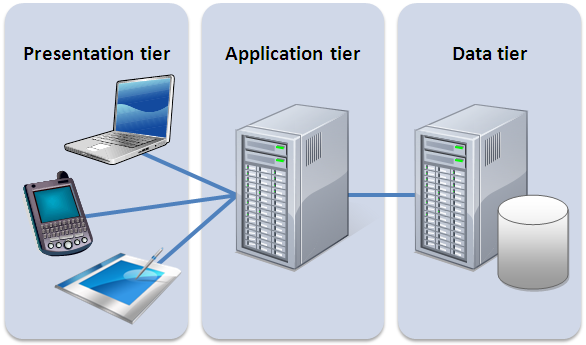
Con esta arquitectura, el cliente puede ser relativamente poco inteligente, con gran parte de la lógica en el sistema (autenticación, navegación de páginas, búsqueda, transacciones) implementada por la aplicación del servidor.
Con una arquitectura sin servidor, esto puede terminar pareciéndose más a esto:
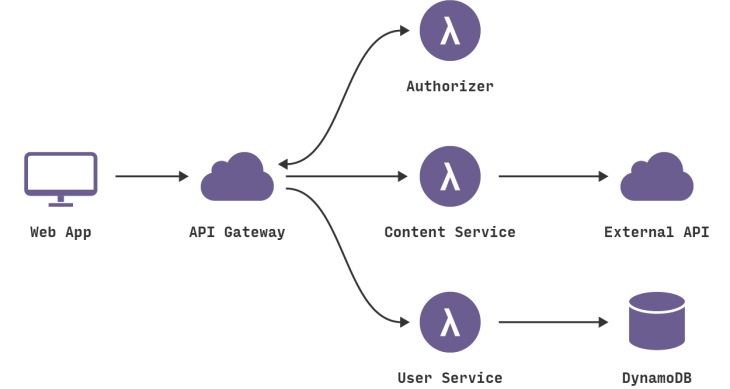
Esta es una representación muy simplificada, pero incluso aquí vemos una serie de cambios significativos:
Hemos eliminado la lógica de autenticación en la aplicación original y la hemos reemplazado con un servicio BaaS de terceros (por ejemplo, Auth0.)
Usando otro ejemplo de BaaS, hemos permitido al cliente acceder directamente a un subconjunto de nuestra base de datos (para listados de productos), que a su vez está totalmente alojado por un tercero (por ejemplo, Google Firebase). Es probable que tengamos un perfil de seguridad diferente para el cliente accede a la base de datos de esta manera que para los recursos del servidor que acceden a la base de datos
Estos dos puntos anteriores implican un tercero muy importante: parte de la lógica que estaba en el servidor del ecommerce está ahora dentro del cliente, por ejemplo, realizar un seguimiento de una sesión de usuario, comprender la estructura de UX de la aplicación, leer de una base de datos y traducirla a una vista utilizable, etc. El cliente está en proceso de convertirse en una aplicación de una sola página.
Es posible que queramos mantener algunas funciones relacionadas con el UX en el servidor, si, por ejemplo, es un proceso intensivo de cómputo o se requiere de un acceso a cantidades significativas de datos. En nuestra tienda de ecommerce, un ejemplo es «buscar». En lugar de tener un servidor en ejecución, como existía en la arquitectura original, podemos implementar una función FaaS que responda a las solicitudes HTTP a través de una puerta de enlace API (que se describe más adelante). Tanto la función de «búsqueda» del cliente como del servidor leen desde la misma base de datos los datos del producto.
Si elegimos utilizar AWS Lambda como nuestra plataforma FaaS, podemos transferir el código de búsqueda desde el servidor original del ecommerce a la nueva función de búsqueda de la tienda sin una reescritura completa, ya que Lambda admite Java y Javascript, nuestros lenguajes de implementación originales.
Finalmente, podemos reemplazar nuestra funcionalidad de «compra» con otra función FaaS separada, eligiendo mantenerla en el lado del servidor por razones de seguridad, en lugar de volver a implementarla en el cliente. También está liderado por una puerta de enlace vía API. La división de diferentes requisitos lógicos en componentes implementados por separado es un enfoque muy común cuando se utiliza FaaS.
Retrocediendo un poco, este ejemplo demuestra otro punto muy importante sobre las arquitecturas sin servidor. En la versión original, todo el flujo, control y seguridad era administrado por la aplicación del servidor central. En la versión sin servidor no hay un árbitro central encargado de estas preocupaciones. En cambio, vemos una preferencia por la coreografía sobre la orquestación, con cada componente desempeñando un papel más consciente de la arquitectura, una idea que también es común en un enfoque de microservicios.
Hay muchos beneficios de este enfoque. Como señala Sam Newman en su libro Building Microservices, los sistemas construidos de esta manera a menudo son «más flexibles y fáciles de cambiar», tanto en su conjunto como a través de actualizaciones independientes de los componentes. Hay una mejor división de preocupaciones y también hay importante ahorro en costes, un punto que Gojko Adzic discute en esta excelente charla.
Por supuesto, un diseño de este tipo es un compromiso: requiere una mejor supervisión distribuida (más sobre esto más adelante), y confiamos más en las capacidades de seguridad de la plataforma subyacente. Fundamentalmente, hay un número mayor de piezas móviles que tenemos que tener en consideración respecto a la aplicación monolítica que teníamos originalmente. Si los beneficios de flexibilidad y costes compensan la complejidad agregada de los múltiples componentes del backend es algo que va a depender mucho del contexto.
Aplicaciones dirigidas por mensajes
Un ejemplo diferente es un servicio de procesamiento de datos en backend.
Supongamos que estás escribiendo una aplicación centrada en el usuario que necesita responder rápidamente a las solicitudes del IU y, en segundo lugar, debe capturar todos los diferentes tipos de actividad de usuario que se están produciendo, para su posterior procesamiento. Piense en un sistema de publicidad online: cuando un usuario hace clic en un anuncio, desea redirigirlo muy rápidamente al objetivo de ese anuncio. Al mismo tiempo, debe recopilar el hecho de que el clic ha ocurrido para que pueda cobrar al anunciante.
Tradicionalmente, la arquitectura puede verse como a continuación. El «Servidor de anuncios» responde de manera síncrona al usuario (no se muestra) y también publica un «mensaje de clic» en un canal. Este mensaje luego se procesa de forma asíncrona mediante una aplicación de «procesador de clics» que actualiza una base de datos, por ejemplo, para disminuir el presupuesto del anunciante.
El cambio en la arquitectura es mucho más pequeño en comparación con el ejemplo anterior: esta es la razón por la cual el procesamiento asíncrono de mensajes es un caso de uso muy popular para las tecnologías sin servidor. Hemos reemplazado una aplicación de consumidor de mensajes de larga duración con una función FaaS. Esta función se ejecuta dentro del contexto controlado por eventos que proporciona el proveedor. Hay que tener en cuenta que el proveedor de la plataforma en la nube proporciona tanto el intermediario de mensajes como el entorno FaaS, los dos sistemas están estrechamente relacionados entre sí.
El entorno FaaS también puede procesar varios mensajes en paralelo mediante la creación de instancias de varias copias del código de función. Dependiendo de cómo escribimos el proceso original, este puede ser un concepto nuevo que debemos considerar.
Desgranando «Función como un servicio»
Ya hemos mencionado mucho a los FaaS, pero es hora de profundizar en lo que realmente significa. Para hacer esto, veamos la descripción de apertura del producto FaaS de Amazon: Lambda. Le he añadido algunos tokens, que ampliaremos.
AWS Lambda le permite ejecutar código sin aprovisionar ni administrar servidores. (1) … Con Lambda, puede ejecutar código para prácticamente cualquier tipo de aplicación o servicio backend (2), todo con administración cero. Simplemente cargas tu código y Lambda se encargará de todo lo necesario para ejecutar (3) y escalar (4) tu código con alta disponibilidad. Puede configurar tu código para que se active automáticamente desde otros servicios de AWS (5) o puede llamarlo directamente desde cualquier aplicación web o móvil (6).
(1) Fundamentalmente, con FaaS se trata de ejecutar código de back-end sin administrar tus propios sistemas de servidor o las aplicaciones residentes en servidor de larga duración. La segunda cláusula, las aplicaciones de servidor de larga duración, es una diferencia clave cuando se compara con otras tendencias en arquitecturas modernas como los contenedores y PaaS (Platform as a Service).
Si volvemos a nuestro ejemplo de procesamiento de clics anterior, FaaS reemplaza el servidor de procesamiento de clics (posiblemente una máquina física, pero definitivamente una aplicación específica) con algo que no necesita un servidor aprovisionado, ni una aplicación que esté ejecutando todo el tiempo.
(2) Las ofertas de FaaS no requieren codificación en un framework o biblioteca específica. Las funciones de FaaS son aplicaciones regulares cuando se trata de lenguaje y entorno. Por ejemplo, las funciones de AWS Lambda pueden implementarse en «primera clase» en Javascript, Python, Go, cualquier lenguaje JVM (Java, Clojure, Scala, etc.) o cualquier lenguaje .NET. Sin embargo, la función Lambda también puede ejecutar otro proceso que se incluye con tu secuencia de implementación, por lo que puede usar cualquier lenguaje que pueda compilarse en un proceso de Unix.
Sin embargo, las funciones de FaaS tienen importantes restricciones de arquitectura, especialmente cuando se trata del estado y la duración de la ejecución.
Consideremos de nuevo nuestro ejemplo de procesamiento de clics. El único código que debe cambiar al pasar a FaaS es el código del «método principal» (inicio), ya que se elimina, y es probable que sea el código específico que es el controlador de mensajes de nivel superior (la implementación de la «interfaz de escucha de mensajes») , pero esto podría ser solo un cambio en la firma del método. El resto del código (por ejemplo, el código que se escribe en la base de datos) no es diferente en un mundo FaaS.
(3) Los despliegues son muy diferentes de los sistemas tradicionales, ya que no tenemos aplicaciones de servidor para ejecutar nosotros mismos. En un entorno FaaS, cargamos el código para nuestra función al proveedor de FaaS, y el proveedor hace todo lo necesario para el aprovisionamiento de recursos, la creación de instancias de máquinas virtuales, la gestión de procesos, etc.
(4) El escalado horizontal es completamente automático, elástico y gestionado por el proveedor. Si tu sistema necesita procesar 100 solicitudes en paralelo, el proveedor lo maneja sin ninguna configuración adicional por tu parte. Los «contenedores de cómputo» que ejecutan tus funciones son efímeros, y el proveedor de FaaS los crea y los destruye por la necesidad del tiempo de ejecución. Lo más importante es que, con FaaS, el proveedor maneja todo el aprovisionamiento y la asignación de recursos subyacentes. El usuario no requiere la administración de clústeres o máquinas virtuales.
Volvamos a nuestro ejemplo de procesador de clics. Pongamos que tenemos un buen día y que los clientes hacen clic en los anuncios diez veces más de lo habitual. Para la arquitectura tradicional, ¿podría nuestra aplicación de procesamiento de clics manejarlo? Por ejemplo, ¿desarrollamos nuestra aplicación para poder manejar múltiples mensajes a la vez? Si lo hiciéramos, ¿una instancia en ejecución de la aplicación sería suficiente para procesar la carga? Si somos capaces de ejecutar múltiples procesos, ¿el escalado es automático o debemos reconfigurarlo manualmente? Con un enfoque de FaaS, todas estas preguntas ya están respondidas: debe escribir la función antes de tiempo para asumir un paralelismo de escalado horizontal, pero desde ese punto en el proveedor de FaaS se encarga automáticamente de todas las necesidades de escalado.
(5) Las funciones en FaaS generalmente son activadas por los tipos de eventos definidos por el proveedor. Con Amazon AWS, tales estímulos incluyen actualizaciones de S3 (archivo / objeto), tiempo (tareas programadas) y mensajes agregados a un bus de mensajes (por ejemplo, Kinesis).
(6) La mayoría de proveedores de serverless computing también permiten que las funciones se activen como respuesta a las solicitudes HTTP entrantes. En AWS, uno típicamente habilita esto mediante el uso de una puerta de enlace API. Usamos una puerta de enlace API en nuestro ejemplo de ecommerce para nuestras funciones de «búsqueda» y «compra». Las funciones también pueden invocarse directamente a través de una API proporcionada por la plataforma, ya sea externamente o desde el mismo entorno de nube, pero este es un uso relativamente poco común.
Desventajas
En otro artículo hablaremos de otras funcionalidades de serverless computing como restricciones en los estados de sesión, duración de ejecución, latencia de arranque y arranque en frío, manejo de gateways API, así como comparaciones y diferencias de serverless con PaaS y contenedores.
Conclusiones
Serverless computing, a pesar del nombre confuso, es un estilo de arquitectura en el que dependemos de la ejecución de nuestros propios sistemas de servidor como parte de nuestras aplicaciones en menor medida de lo habitual. Lo hacemos a través de dos técnicas: BaaS, donde integramos estrechamente los servicios de aplicaciones remotas de terceros directamente en el frontend de nuestras aplicaciones, y FaaS, que mueve el código del lado del servidor de los componentes de ejecución prolongada a las instancias de funciones efímeras.
Serverless no es el enfoque correcto para todos los problemas, así que desconfía de cualquiera que diga que reemplazará todas sus arquitecturas existentes. Hay que ir con cuidado si nos lanzamos a sistemas serverless ahora, especialmente en el ámbito FaaS. Si bien hay muchos beneficios (de escalamiento y esfuerzo de implementación guardado) para ser aprovechados, también hay ciertas pegas (de depuración y monitoreo) que nos podemos encontrar.
La arquitectura de Serverless tiene aspectos positivos significativos, que incluyen una reducción de los costos operativos y de desarrollo, una gestión operacional más sencilla y un menor impacto ambiental. Pero creo que el beneficio más importante es el ciclo reducido de feedback de la creación de nuevos componentes de aplicaciones. Como fanático de los enfoques «lean», en gran parte porque creo que hay mucho valor en poner la tecnología frente a un usuario final tan pronto como sea posible para obtener retroalimentación lo antes posible, y el tiempo reducido en el mercado que viene con Serverless encaja perfectamente con esta filosofía.
Los servicios sin servidor, y nuestra comprensión de cómo usarlos, se encuentran hoy (2019) en la “fase un poco incómoda” de la adolescencia. Habrá muchos avances en el campo en los próximos años, y será fascinante ver cómo Serverless encaja en nuestro conjunto de herramientas de arquitecturas.


